Constrained conditional model
A constrained conditional model (CCM) is a machine learning and inference framework that augments the learning of conditional (probabilistic or discriminative) models with declarative constraints. The constraint can be used as a way to incorporate expressive prior knowledge into the model and bias the assignments made by the learned model to satisfy these constraints. The framework can be used to support decisions in an expressive output space while maintaining modularity and tractability of training and inference.
Models of this kind have recently attracted much attention within the natural language processing (NLP) community. Formulating problems as constrained optimization problems over the output of learned models has several advantages. It allows one to focus on the modeling of problems by providing the opportunity to incorporate domain-specific knowledge as global constraints using a first order language. Using this declarative framework frees the developer from low level feature engineering while capturing the problem's domain-specific properties and guarantying exact inference. From a machine learning perspective it allows decoupling the stage of model generation (learning) from that of the constrained inference stage, thus helping to simplify the learning stage while improving the quality of the solutions. For example, in the case of generating compressed sentences, rather than simply relaying on a language model to keep in the sentence the most commonly used ngrams, constraints can be use to make sure that if a modifier is kept in the compressed sentence, its subject will also be kept.
Contents |
Motivation
Making decisions in many domains (such as natural language processing and computer vision problems) often involve assigning values to sets of interdependent variables where the expressive dependency structure can influence, or even dictate, what assignments are possible. These settings are applicable to Structured Learning problems such as semantic role labeling but also for cases that require making use of multiple pre-learned components, such as summarization, textual entailment and question answering. In all these cases, it is natural to formulate the decision problem as a constrained optimization problem, with an objective function that is composed of learned models, subject to domain or problem specific constraints.
Constrained conditional models is a learning and inference framework that augments the learning of conditional (probabilistic or discriminative) models with declarative constraints (written, for example, using a first-order representation) as a way to support decisions in an expressive output space while maintaining modularity and tractability of training and inference. These constraints can express either hard restrictions, completely prohibiting some assignments, or soft restrictions, penalizing unlikely assignments. In most applications of this framework in NLP, following [1], Integer Linear Programming (ILP) was used as the inference framework, although other algorithms can be used for that purpose.
Formal Definition
Given a set of feature functions 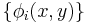 and a set of constraints
and a set of constraints 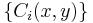 , defined over an input structure
, defined over an input structure 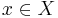 and an output structure
and an output structure  , a constraint conditional model is characterized by two weight vectors, w and
, a constraint conditional model is characterized by two weight vectors, w and 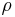 , and is defined as the solution to the following optimization problem:
, and is defined as the solution to the following optimization problem:
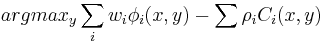 .
.
Each constraint 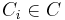 is a boolean mapping indicating if the joint assignment
is a boolean mapping indicating if the joint assignment 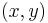 violates a constraint, and is the penalty incurred for violating the constraints. Constraints assigned an infinite penalty are known as hard constraints, and represent unfeasible assignments to the optimization problem.
violates a constraint, and is the penalty incurred for violating the constraints. Constraints assigned an infinite penalty are known as hard constraints, and represent unfeasible assignments to the optimization problem.
Training paradigms
Learning local vs. global models
The objective function used by CCMs can be decomposed and learned in several ways, ranging from a complete joint training of the model along with the constraints to completely decoupling between the learning and the inference stage. In the latter case, several local models are learned independently and the dependency between these models is considered only at decision time via a global decision process. The advantages of each approach are discussed in [2], which studies the two training paradigms: (1) local models: L+I (learning+inference) and (2) global model: IBT (Inference based training), and shows both theoretically and experimentally that while IBT (joint training) is best in the limit, under some conditions (basically, ”good” components”) L+I can generalize better.
The ability of CCM to combine local model is especially beneficial in cases where joint leaning is computationally intractable or when training data is not available for joint learning. This flexibility distinguishes CCM from other learning frameworks (e.g., Markov logic network) which emphasize joint training.
Minimally supervised CCM
CCM can help reduce supervision by using domain knowledge (expressed as constraints) to drive learning. These setting were studied in [3] and [4]. These works introduce semi-supervised Constraints Driven Learning (CODL) and show that by incorporating domain knowledge the performance of the learned model improves significantly.
Learning over latent representations
CCMs were also applied to latent learning frameworks, where the learning problem is defined over a latent representation layer. Since the notion of a correct representation is inherently ill-defined no gold-labeled data regarding the representation decision is available to the learner. Identifying the correct (or optimal) learning representation is viewed as a structured prediction process and therefore modeled as a CCM. This problem was studied by several papers, in both supervised [5] and unsupervised [6] settings and in all cases showed that explicitly modeling the interdependencies between representation decisions via constraints results in an improved performance.
Integer linear programming for natural language processing applications
The advantages of the CCM declarative formulation and the availability of off-the-shelf solvers have led to a large variety of natural language processing tasks being formulated within framework, including semantic role labeling [7], syntactic parsing [8], coreference resolution [9], summarization [10] [11] [12]., transliteration [13], natural language generation [14] and joint information extraction [15] [16].
Most of these works use an integer linear programming (ILP) solver to solve the decision problem. Although theoretically solving an Integer Linear Program is exponential in the size of the decision problem in practice using state-of-the-art solvers and approximated inference techniques [17] large scale problems can be solved efficiently.
The key advantage of using an ILP solver for solving the optimization problem defined by a constrained conditional model is the declarative formulation used as input for the ILP solver, consisting of a linear objective function and a set of linear constraints.
Resources
- CCM Tutorial Integer Linear Programming in NLP – Constrained Conditional Models, NAACL-2010
- CCM Software Learning Based Java
External links
- University of Illinois Cognitive Computation Group
- Workshop on Integer Linear Programming for Natural Language Processing, NAACL-2009
References
- ^ Dan Roth and Wen-tau Yih, "A Linear Programming Formulation for Global Inference in Natural Language Tasks." CoNLL, (2004).
- ^ Vasin Punyakanok and Dan Roth and Wen-Tau Yih and Dav Zimak, "Learning and Inference over Constrained Output." IJCAI, (2005).
- ^ Ming-Wei Chang and Lev Ratinov and Dan Roth, "Guiding Semi-Supervision with Constraint-Driven Learning." ACL, (2007).
- ^ Ming-Wei Chang and Lev Ratinov and Dan Roth, "Constraints as Prior Knowledge." ICML Workshop on Prior Knowledge for Text and Language Processing}, (2008).
- ^ Ming-Wei Chang and Dan Goldwasser and Dan Roth and Vivek Srikumar, " Discriminative Learning over Constrained Latent Representations." NAACL, (2010).
- ^ Ming-Wei Chang Dan Goldwasser Dan Roth and Yuancheng Tu, "Unsupervised Constraint Driven Learning For Transliteration Discovery." NAACL, (2009).
- ^ Vasin Punyakanok, Dan Roth, Wen-tau Yih and Dav Zimak, "Semantic Role Labeling via Integer Linear Programming Inference." COLING, (2004).
- ^ Kenji Sagae and Yusuke Miyao and Jun’ichi Tsujii, "HPSG Parsing with Shallow Dependency Constraints." ACL, (2007).
- ^ Pascal Denis and Jason Baldridge, "Joint Determination of Anaphoricity and Coreference Resolution using Integer Programming." NAACL-HLT, (2007).
- ^ James Clarke and Mirella Lapata, "Global Inference for Sentence Compression: An Integer Linear Programming Approach." Journal of Artificial Intelligence Research (JAIR), (2008).
- ^ Katja Filippova and Michael Strube, "Dependency Tree Based Sentence Compression." INLG, (2008).
- ^ Katja Filippova and Michael Strube, "Sentence Fusion via Dependency Graph Compression." EMNLP, (2008).
- ^ Dan Goldwasser and Dan Roth, "Transliteration as Constrained Optimization." EMNLP, (2008).
- ^ Regina Barzilay and Mirrela Lapata, "Aggregation via Set Partitioning for Natural Language Generation." NAACL, (2006).
- ^ Dan Roth and Wen-tau Yih, "A Linear Programming Formulation for Global Inference in Natural Language Tasks." CoNLL, (2004).
- ^ Yejin Choi and Eric Breck and Claire Cardie, "Joint Extraction of Entities and Relations for Opinion Recognition." EMNLP, (2006).
- ^ André F. T. Martins, Noah A. Smith, and Eric P. Xing , "Concise Integer Linear Programming Formulations for Dependency Parsing ." ACL, (2009).